Sakana Fuguとは(仕組みを解説)
Sakana Fugu とは、東京に拠点を置くAI企業 Sakana AI が2026年6月22日に公開した、複数の高性能AIモデルを1つのモデルのように扱えるマルチエージェントシステムです。ここではまず、その正体と仕組み、提供形態、そして利用前に知っておきたい制約を順に整理します。
Sakana Fugu の定義と仕組み(単一APIで複数モデルを自動編成)
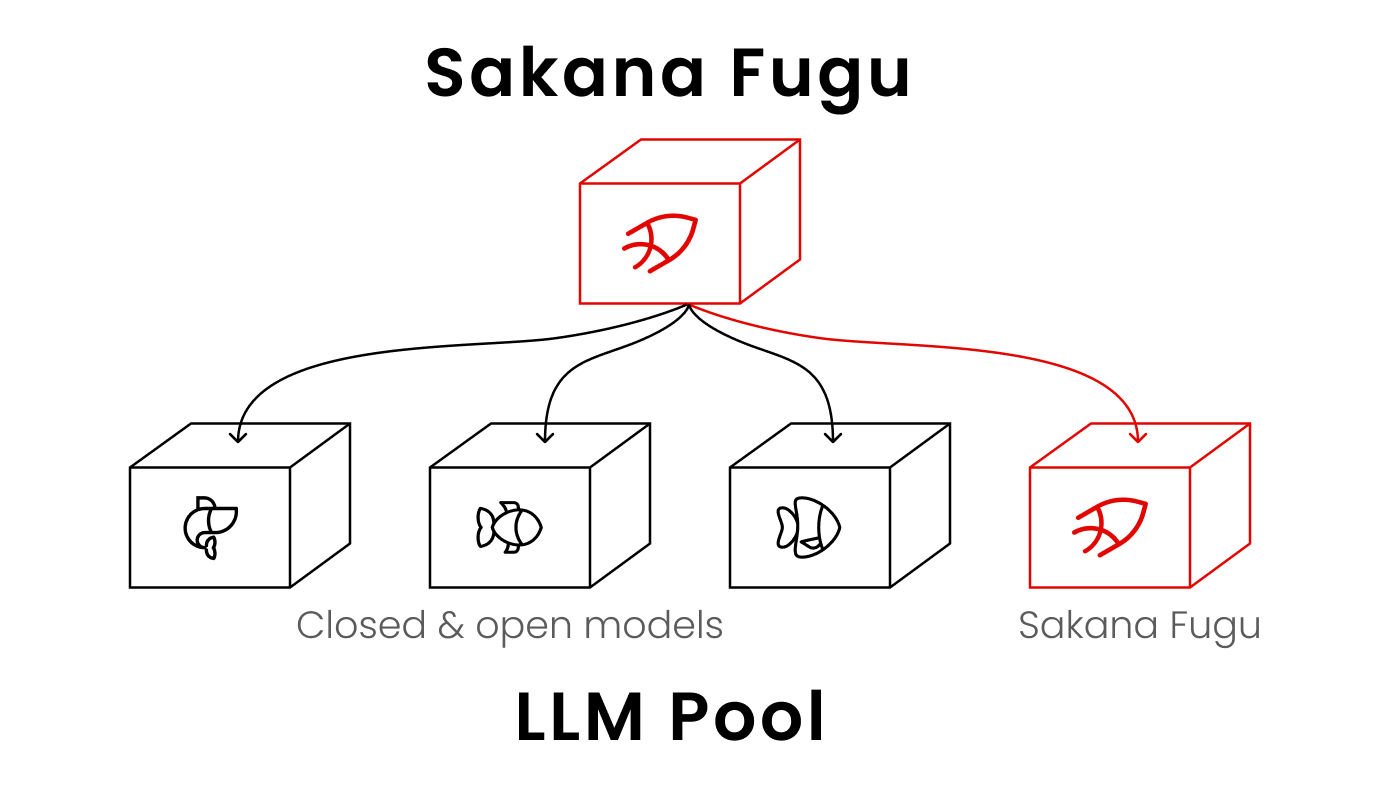
Sakana Fugu は、単体の大規模言語モデル(LLM=文章を理解し生成するAI)ではありません。複数の高性能モデルを「エージェントプール」としてまとめ、入力に応じて最適なモデルを自動で選び、組み合わせて回答を作る仕組みです。Sakana Fugu は、複数のフロンティアAIモデルを1つのAPIから束ね、1つのモデルのように振る舞うシステムです。 利用者から見れば呼び出すのは1つのエンドポイントだけで、内部で複数モデルが「考える役」「実行する役」「検証する役」に分かれて協調します。
"Sakana Fugu is a multi-agent system that behaves like a single model." / "accessible through a single model API." — Sakana Fugu リリース本文より
この自動編成は、人が固定のワークフローを組むのではなく、タスクごとに専門エージェントを学習で編成する点が特徴です。背景には、軽量なコーディネーターが複数のLLMを複数ターンにわたって統括する「TRINITY」と、強化学習で自然言語ベースの協調戦略を見つける「Conductor」という、ICLR 2026 で参照される2本の研究があるとしています。
具体的な流れをイメージするとわかりやすくなります。たとえば「この仕様書からテストコードを書いて」という1つの頼みごとを送ると、Fugu は内部でタスクを分解し、設計が得意なモデルに方針を立てさせ、別のモデルに実装を書かせ、さらに検証役のモデルに誤りを点検させます。利用者にはこの過程は見えず、最終的な回答だけが1つのAPIから返ってきます。単体モデルなら1つの頭で全工程をこなすところを、Fugu は得意分野の異なる複数の頭に分担させることで、平均的な品質を底上げしようとする発想です。生成AIの全体像や他モデルとの位置づけは、あわせて Claude とは(Anthropicの生成AI)の解説記事 も参考になります。
Fugu と Fugu Ultra の2種類
Sakana Fugu には、標準版の「Fugu」と上位版の「Fugu Ultra」の2モデルがあります。どちらも OpenAI 互換の API から利用でき、用途や負荷に合わせて選べます。コストを抑えたい日常利用なら Fugu、難関タスクで最高精度を狙うなら Fugu Ultra、という選び分けが基本です。
"At launch, Sakana Fugu comes in two models, so you can match the system to your workload." — Sakana Fugu リリース本文より
OpenAI 互換 API という点は実務上の利点です。既存の OpenAI 向けに書いたコードのエンドポイントを差し替えるだけで試せるため、移行コストが小さく済みます。
Sakana Fuguのデメリット(モデル非開示)
便利さの一方で、Sakana Fugu には見落としやすい制約があります。各回答で実際にどのモデルが選ばれ、どう連携したのかは利用者に開示されません。どのモデルが使われたかを追跡できないため、出力の根拠を厳密に管理したい業務では扱いにくい場面があります。
"The specific models Fugu selects and how it coordinates them are proprietary, so this routing information is not exposed by design." — Fugu 製品ページより
このため、監査ログや再現性が重視される領域(医療・金融・法務など)では、単一モデルを明示的に呼ぶ運用のほうが向く場合があります。逆に、品質を一定以上に保ちつつ手間を減らしたい一般的な業務では、内部のモデル選択を気にせず使える点がそのまま利点になります。
Sakana Fuguのベンチマーク性能
棒の長さは0〜100スコアで統一(高いほど高性能)。数値は Sakana AI 公開のベンチマーク値。
Sakana Fugu の実力は、Sakana AI が公開したベンチマークで確認できます。ここでは主要AIとの比較、Anthropic 最上位モデルとの関係、そして数値を読むときの注意点を見ていきます。
主要AIモデル(Opus 4.8・GPT 5.5・Gemini 3.1 Pro)との比較
公式によると、Fugu モデル群は一般提供されているフロンティアモデルを一貫して上回るとされています。Fugu Ultra はソフトウェア開発の SWE-Bench Pro で73.7を記録し、Opus 4.8 の69.2、GPT 5.5 の58.6を上回りました。
"Fugu Models consistently outperform frontier models Gemini 3.1 Pro (high), Opus 4.8 (max), and GPT 5.5 (xhigh)" — Sakana Fugu リリース本文より
コード生成の LiveCodeBench では Fugu Ultra が93.2、標準版 Fugu が92.9で、Gemini 3.1 Pro の88.5を超えています。科学知識の GPQA-Diamond では95.5、ターミナル操作の Terminal Bench 2.1 では82.1と、いずれも主要3モデルを上回りました。コーディングと科学・推論の難関ベンチマークでは、Fugu Ultra が Opus 4.8・GPT 5.5・Gemini 3.1 Pro を総じて上回っています。
「Fable 5を上回る」ではない点に注意(肩を並べる関係)
ここで重要なのは、Sakana AI 自身が「Fable 5 を上回る」とは述べていない点です。公式の表現は「肩を並べる(shoulder-to-shoulder)」であり、明確に上回るとしているのは一般提供モデルに対してです。「主要AIは上回る、Anthropic 最上位とは互角」が、公式が示した正確な立ち位置です。
"Our Fugu Ultra model stands shoulder-to-shoulder with leading models like Fable 5 and Mythos Preview" / "Neither of them is in Fugu's agent pool as they are not publicly accessible." — Sakana Fugu リリース本文より
そもそも Fable 5 と Mythos Preview は一般に利用できないため、Fugu のエージェントプールには含まれていません。つまり Fugu は、入手できる範囲のモデルだけを束ねて、入手しづらい最上位モデルと同等の水準に届いた、という構図です。海外メディアや国内の紹介記事には「Fable 5 を上回る」と強めに書く例も見られますが、一次情報に当たると主張の射程はもう少し慎重だと分かります。同じ最上位モデルである Claude Opus 4.8 のリリース解説 とあわせて読むと、両者の位置づけが立体的に見えてきます。
ベンチマークの読み方と注意点
ベンチマークは万能の指標ではありません。上のグラフを見ると、SWE-Bench Pro では Fable 5 が86.0で Fugu Ultra の73.7を上回り、Humanity's Last Exam でも Fable 5 が53.3で Fugu Ultra の50.0を上回っています。 一方で Terminal Bench・LiveCodeBench・CharXiv では Fugu Ultra が上回っており、benchmarkごとに勝ち負けが入れ替わります。これが「肩を並べる」の実態です。
数値を読むときは、(1) どのモデルが比較対象に入っているか、(2) 一回の試行か複数試行の平均か、(3) 自分の用途に近いベンチマークか、の3点を確認すると誤解を避けられます。コード中心ならコード系(SWE-Bench・LiveCodeBench)、調査・推論中心なら GPQA・Humanity's Last Exam を重く見る、といった具合に、用途に合うベンチを基準にするのが実務的です。
Sakana Fuguの料金・比較
主要AIサービスの標準プラン 月額(ドル)
Sakana Fugu(青)はサブスク下限。棒の長さは月額(ドル)。出典: 各社公式(2026年6月時点)。
性能と並んで気になるのが料金と、Sakana Fugu ならではの価値です。ここでは料金プラン、主要AIツールとの料金比較、そして「特定モデルが消えても止まらない」という独自の設計思想を整理します。
料金プラン(サブスクリプション+従量課金)
Sakana Fugu の料金は、日常利用向けのサブスクリプションと、重い処理・企業向けの従量課金(pay-as-you-go)の2本立てです。月額20〜200ドルのサブスクリプションと従量課金という構成で、主要AIツールの標準プラン(月額20ドル前後)と同水準に収まっています。
"subscription tiers for everyday use and a pay-as-you-go plan for heavier and enterprise workloads." — Sakana Fugu リリース本文より
| Sakana Fugu のプラン | 料金 | 主な用途 |
|---|---|---|
| サブスクリプション | 月額 20〜200ドル(複数階層) | 日常利用 |
| 従量課金(pay-as-you-go) | Fugu Ultra: 入力 5ドル / 出力 30ドル(100万トークンあたり) | 重い処理・企業向け |
複数のエージェントが同時に動いても料金は積み上がらず、最上位モデルのレートのみが請求される方式とされています。なお、EU/EEA 域内ではデータ保護規制への対応を進めている最中で、現時点では利用できないとされています。
主要AIツールとの料金比較
Sakana Fugu の価格帯を、主要なAIサービスの月額と並べると位置づけが分かりやすくなります。Sakana Fugu の料金は ChatGPT・Claude・Gemini といった主要AIの標準プランとほぼ同じ水準で、価格だけで突出して有利・不利になることはありません。
| ツール(提供元) | 標準プラン(月額) | 上位プラン(月額) |
|---|---|---|
| Sakana Fugu(Sakana AI) | 20ドル〜(サブスク)+従量課金 | 200ドル +従量課金 |
| ChatGPT(OpenAI) | Plus 20ドル | Pro 200ドル |
| Claude(Anthropic) | Pro 20ドル | Max 200ドル |
| Gemini(Google) | AI Pro 19.99ドル | AI Ultra 250ドル |
| Grok(xAI) | SuperGrok 30ドル | Heavy 300ドル |
| Perplexity | Pro 20ドル | — |
※各社公式の料金ページに基づく2026年6月時点の代表的な月額です。為替・改定で変わるため、最新は各社公式をご確認ください。個別ツールの詳しい使い方や料金は ChatGPT(GPT-5)の解説記事 もあわせて参考になります。料金が同水準である以上、選ぶ基準は「価格」ではなく「単一モデルに依存したくないか」「どのモデルが使われたか把握したいか」に移ります。
Sakana Fuguのメリット(依存リスク低減)
Sakana Fugu の最大の差別化は、特定モデルへの依存リスクを下げられる点です。輸出規制などで特定モデルが突然使えなくなっても、別のモデルへ自動的に切り替えて処理を続けられる点が、この設計の最大の狙いです。
"access can shift or disappear overnight due to changing regulatory boundaries, export controls, and foreign policies." — Sakana Fugu リリース本文より
公式は、Anthropic の Fable や Mythos に課された輸出規制を例に、アクセスは規制・外交方針の変化によって一夜にして変わったり消えたりしうると述べています。Fugu は複数モデルを動的に組み合わせる仕組みのため、ある提供元やモデルが使えなくなっても、別のモデルへ柔軟に切り替えて迂回できるとしています。単一モデルに事業を賭けるリスクを避けたい場合、この「止まらなさ」は料金や瞬間的なベンチマークよりも重要な判断材料になり得ます。
Sakana Fuguの使い方・まとめ
最後に、日本のユーザーが Sakana Fugu をどう位置づければよいかを、対象者別の含意・導入前の注意点・出典の順にまとめます。
Sakana Fuguの使い方・活用シーン
東京発の Sakana AI がオーケストレーション型のサービスを出した意味は、日本の個人開発者や中小企業にとって小さくありません。特定の海外モデル1本に依存せず、価格改定・提供停止・規制変更といった外部要因に事業を左右されにくくしたい場合、Sakana Fugu は有力な選択肢になります。 具体的には、社内ツールやSaaSのバックエンドにAIを組み込みたいが、どのモデルが最適か選びきれない・将来のモデル変更に追従する手間を減らしたい、というケースで効果を発揮します。
たとえば、問い合わせ対応の自動化や社内文書の要約といった業務を考えてみます。担当者一人で運用する小規模なチームでは、モデルごとの強みを比較し続け、料金改定や提供終了のたびに乗り換えを検討するだけでも負担になります。Fugu のように1つのAPIの裏で複数モデルを使い分けてくれる仕組みなら、こうした「どのモデルを使うか」という運用判断そのものを任せられます。逆に、すでに用途とモデルが定まっていて単価を1円単位で最小化したいだけなら、目的のモデルのAPIを直接呼ぶほうが安く済む場合もあります。要は、選定や追従の手間を減らしたい段階では Fugu、最適解が固まってコストを詰める段階では単一モデル直叩き、という使い分けが現実的です。
導入前に確認すべき注意点
導入を判断する前に、3点を確認しておくと失敗しにくくなります。「どのモデルが使われたか追跡できない」「EU/EEA では現時点で使えない」「用途次第では単一モデル直叩きのほうが安い」の3つが、Sakana Fugu の主な留意点です。 監査ログや再現性が必須の業務、EU 圏の利用者を抱える事業、コストを1円単位で詰めたい用途では、この制約が効いてきます。逆に、品質を一定に保ちつつ運用の手間とモデル選定の悩みを減らしたい一般的な業務であれば、これらの制約は許容範囲に収まることが多いはずです。手元のドキュメントをAIに渡して試すところから始めるなら、まず資料を整える ローカルLLMの実務活用ガイド も参考になります。
Sakana Fuguのまとめと公式ソース
本記事の内容は、以下の一次情報(公式発表)をもとにまとめています。料金・モデル・仕様は更新されるため、導入前に必ず公式の最新情報をご確認ください。
Fugu のような大規模言語モデルに長文ドキュメントを渡す際は、あらかじめ Markdown 形式に整えておくと、見出し階層や表構造が保たれて精度が上がりやすくなります。Webページをそのまま整形したいときは、次のツールが役立ちます。