What Is Sakana Fugu (How It Works)
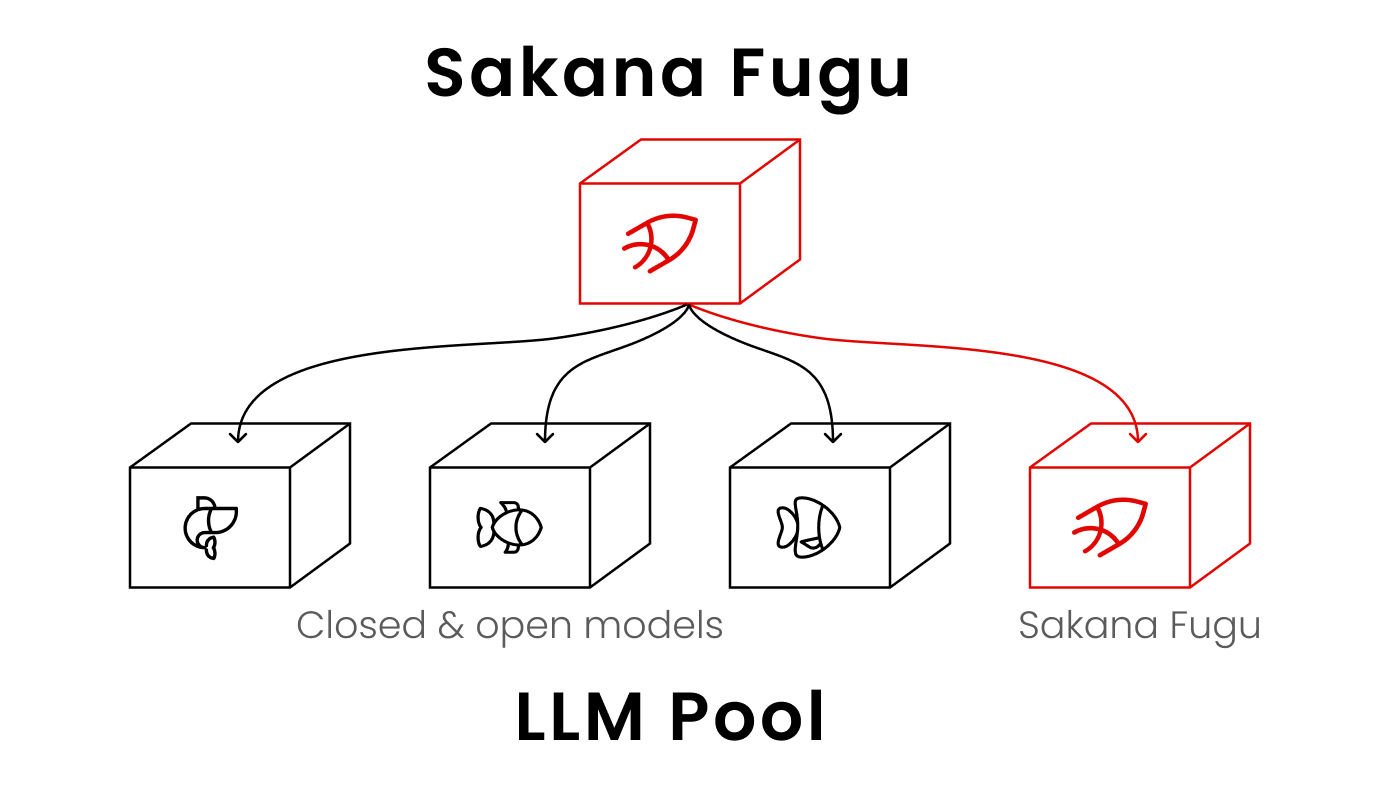
Sakana Fugu is a multi-agent system released on June 22, 2026 by Tokyo-based Sakana AI that lets you treat multiple high-performance AI models as if they were a single model. First, let's go through what it actually is, how it works, how it is offered, and the constraints worth knowing before you use it.
How Sakana Fugu Works (One API That Orchestrates Multiple Models)
Sakana Fugu is not a single large language model (LLM — an AI that understands and generates text). It groups multiple high-performance models into an "agent pool," automatically picks the most suitable models for the input, and combines them to produce an answer. Sakana Fugu bundles multiple frontier AI models behind a single API and behaves like one model. From the user's side you only call one endpoint, while internally several models split into roles such as "thinker," "worker," and "verifier" and cooperate.
"Sakana Fugu is a multi-agent system that behaves like a single model." / "accessible through a single model API." — from the Sakana Fugu release
This orchestration is notable because, rather than a human assembling a fixed workflow, it learns to compose specialized agents per task. Behind it are two research works referenced at ICLR 2026: "TRINITY," in which a lightweight coordinator manages multiple LLMs over multiple turns, and "Conductor," which uses reinforcement learning to discover natural-language coordination strategies.
A concrete flow makes it easier to picture. If you send a single request like "write test code from this spec," Fugu internally breaks the task down, has a model good at design draft the plan, has another model write the implementation, and has a verifier model check for mistakes. The user does not see this process, and only the final answer is returned from one API. Where a single model would handle the whole pipeline with one "head," Fugu splits it across multiple heads with different strengths to raise the average quality. For an overview of generative AI and how other models compare, see also our guide to Claude (Anthropic's generative AI).
Two Versions: Fugu and Fugu Ultra
Sakana Fugu has two models: the standard "Fugu" and the higher-tier "Fugu Ultra." Both are available via an OpenAI-compatible API, so you can choose based on your use case and load. The basic choice is Fugu for cost-conscious everyday use, and Fugu Ultra when you want maximum accuracy on hard tasks.
"At launch, Sakana Fugu comes in two models, so you can match the system to your workload." — from the Sakana Fugu release
The OpenAI-compatible API is a practical advantage: you can try it by just swapping the endpoint of code already written for OpenAI, keeping migration cost low.
A Downside of Sakana Fugu (Model Opacity)
For all its convenience, Sakana Fugu has an easy-to-miss constraint: which model was actually selected for each answer, and how they were coordinated, is not disclosed to the user. Because you cannot trace which model was used, it can be awkward for work where you need to strictly manage the basis of the output.
"The specific models Fugu selects and how it coordinates them are proprietary, so this routing information is not exposed by design." — from the Fugu product page
For domains where audit logs and reproducibility matter (medical, finance, legal, etc.), explicitly calling a single model may be a better fit. Conversely, for general work where you want to keep quality at a certain level while reducing effort, not having to worry about the internal model selection is itself a benefit.
Sakana Fugu Benchmark Performance
Bar length is on a unified 0–100 score (higher is better). Figures are benchmark values published by Sakana AI.
Sakana Fugu's capability can be checked against the benchmarks Sakana AI published. Here we look at the comparison with major AIs, the relationship with Anthropic's top-tier models, and the cautions when reading the numbers.
Comparison With Major AI Models (Opus 4.8, GPT 5.5, Gemini 3.1 Pro)
According to Sakana AI, the Fugu models consistently outperform the generally available frontier models. Fugu Ultra scored 73.7 on the software-engineering benchmark SWE-Bench Pro, beating Opus 4.8's 69.2 and GPT 5.5's 58.6.
"Fugu Models consistently outperform frontier models Gemini 3.1 Pro (high), Opus 4.8 (max), and GPT 5.5 (xhigh)" — from the Sakana Fugu release
On the code-generation benchmark LiveCodeBench, the standard Fugu scored 92.9 and Fugu Ultra 93.2, beating Gemini 3.1 Pro's 88.5. On the graduate-level science benchmark GPQA-Diamond it reached 95.5, and on Terminal Bench 2.1 it reached 82.1 — outperforming the three major models in each case. On the hard coding, science, and reasoning benchmarks, Fugu Ultra generally outperforms Opus 4.8, GPT 5.5, and Gemini 3.1 Pro.
Why It Is Not "Beating Fable 5" (A Shoulder-to-Shoulder Relationship)
What matters here is that Sakana AI itself does not claim to "beat Fable 5." The official wording is "shoulder-to-shoulder," and it only clearly claims to outperform the generally available models. "Outperforms the major AIs, on par with Anthropic's top tier" is the precise position the company presents.
"Our Fugu Ultra model stands shoulder-to-shoulder with leading models like Fable 5 and Mythos Preview" / "Neither of them is in Fugu's agent pool as they are not publicly accessible." — from the Sakana Fugu release
In fact, Fable 5 and Mythos Preview are not publicly available, so they are not in Fugu's agent pool. In other words, Fugu reaches a level comparable to top-tier models that are hard to access, using only the models that are available. Some overseas and domestic write-ups put it more strongly as "beats Fable 5," but going to the primary source, the claim is more measured. Reading it together with our release explainer for Claude Opus 4.8, another top-tier model, gives a fuller picture of where both stand.
How to Read the Benchmarks, and Cautions
Benchmarks are not an all-purpose metric. Looking at the chart above, on SWE-Bench Pro, Fable 5's 86.0 beats Fugu Ultra's 73.7, and on Humanity's Last Exam, Fable 5's 53.3 beats Fugu Ultra's 50.0. On Terminal Bench, LiveCodeBench, and CharXiv, on the other hand, Fugu Ultra is ahead, so the wins and losses swap by benchmark. This is what "shoulder-to-shoulder" actually looks like.
When reading the numbers, checking three things helps avoid misunderstanding: (1) which models are in the comparison, (2) whether it is a single run or an average of multiple runs, and (3) whether the benchmark is close to your own use case. If you mainly write code, weight the code benchmarks (SWE-Bench, LiveCodeBench); if you mainly do research and reasoning, weight GPQA and Humanity's Last Exam.
Sakana Fugu Pricing & Comparison
Standard-plan monthly price of major AI services (USD)
Sakana Fugu (blue) is the subscription floor. Bar length is the monthly price (USD). Source: each provider's official pricing (as of June 2026).
Alongside performance, pricing and Sakana Fugu's unique value are the next concerns. Here we cover the pricing plans, the comparison with major AI tools, and the design idea of "not stopping even if a specific model disappears."
Pricing Plans (Subscription + Pay-as-you-go)
Sakana Fugu's pricing has two parts: a subscription for everyday use and pay-as-you-go for heavier and enterprise workloads. With a USD 20–200/month subscription plus pay-as-you-go, it lands at roughly the same level as the standard plans of major AI tools (around USD 20/month).
"subscription tiers for everyday use and a pay-as-you-go plan for heavier and enterprise workloads." — from the Sakana Fugu release
| Sakana Fugu plan | Price | Main use |
|---|---|---|
| Subscription | USD 20–200/month (multiple tiers) | Everyday use |
| Pay-as-you-go | Fugu Ultra: input $5 / output $30 (per 1M tokens) | Heavy / enterprise workloads |
Even when multiple agents run at once, billing does not stack — only the top model's rate is charged. Note that within the EU/EEA it is currently unavailable while data-protection compliance is in progress.
Comparison With Major AI Tools
Placing Sakana Fugu's price band next to major AI services makes its position clearer. Sakana Fugu's pricing is about the same as the standard plans of ChatGPT, Claude, and Gemini, so price alone makes it neither a standout bargain nor expensive.
| Tool (provider) | Standard plan (monthly) | Higher plan (monthly) |
|---|---|---|
| Sakana Fugu (Sakana AI) | $20+ (subscription) + pay-as-you-go | $200 + pay-as-you-go |
| ChatGPT (OpenAI) | Plus $20 | Pro $200 |
| Claude (Anthropic) | Pro $20 | Max $200 |
| Gemini (Google) | AI Pro $19.99 | AI Ultra $250 |
| Grok (xAI) | SuperGrok $30 | Heavy $300 |
| Perplexity | Pro $20 | — |
*Representative monthly prices as of June 2026 based on each provider's official pricing pages. They change with exchange rates and revisions, so check each provider's official page for the latest. For details on individual tools, see our ChatGPT (GPT-5) guide. Since pricing is at the same level, the deciding factor shifts from "price" to "whether you want to avoid depending on a single model" and "whether you want to know which model was used."
A Benefit of Sakana Fugu (Reduced Dependency Risk)
Sakana Fugu's biggest differentiator is that it can lower the risk of depending on a specific model. If a specific model suddenly becomes unavailable due to export controls and the like, it automatically switches to another model and keeps processing — that is the core aim of this design.
"access can shift or disappear overnight due to changing regulatory boundaries, export controls, and foreign policies." — from the Sakana Fugu release
Using the export controls imposed on Anthropic's Fable and Mythos as an example, Sakana AI says access can shift or disappear overnight due to changes in regulations and foreign policy. Because Fugu dynamically combines multiple models, even if one provider or model becomes unavailable, it can flexibly switch to another and route around it. If you want to avoid betting your business on a single model, this "not stopping" can be a more important factor than price or a momentary benchmark.
How to Use Sakana Fugu (Summary)
Finally, here is how users can position Sakana Fugu, organized by audience, pre-adoption cautions, and sources.
How to Use Sakana Fugu / Use Cases
That Tokyo-born Sakana AI shipped an orchestration-type service is not a small thing for individual developers and small businesses. If you want to avoid depending on a single foreign model and not let price revisions, service discontinuation, or regulatory changes swing your business, Sakana Fugu is a strong option. Concretely, it shines when you want to embed AI into the backend of an internal tool or SaaS but can't decide which model is best, or want to cut the effort of keeping up with future model changes.
For example, consider automating inquiry handling or summarizing internal documents. For a small team run by a single person, just comparing each model's strengths and reviewing a switch every time prices change or a service ends is a burden. A mechanism like Fugu, which uses multiple models behind one API, lets you hand off the very decision of "which model to use." Conversely, if your use case and model are already fixed and you only want to minimize unit cost to the last cent, calling the target model's API directly may be cheaper. In short: Fugu when you want to cut the effort of selection and keeping up, and a single model directly once the optimal answer is fixed and you're squeezing cost.
Cautions Before Adoption
Checking three points before deciding to adopt helps you avoid mistakes. The three main caveats of Sakana Fugu are: "you can't trace which model was used," "it's currently unavailable in the EU/EEA," and "depending on the use case, calling a single model directly is cheaper." For work that requires audit logs and reproducibility, businesses with EU users, or use cases where you squeeze cost to the last cent, these constraints will bite. Conversely, for general work where you want to keep quality steady while reducing operational effort and the headache of model selection, these constraints often stay within an acceptable range. If you want to start by feeding your documents to an AI, our practical guide to local LLMs, which covers preparing materials, is also useful.
Sakana Fugu Summary & Official Source
This article is based on the following primary source (official announcement). Pricing, models, and specs are updated, so always check the latest official information before adopting.
When feeding long documents to a large language model like Fugu, converting them to Markdown beforehand helps preserve heading structure and tables and tends to improve accuracy. To clean up a web page as-is, the following tool helps.